MapReduce: Simplified Data Processing on Large Clusters
Processing a very large input dataset on a single machine can be time-consuming and inefficient. For example, if an error occurs during processing, you might have to start over. An alternative is to adopt a distributed system and by extension its challenges.
This paper authored by Jeffery Dean and Sanjay in 2004 implements an abstraction that lets you express your computation using two simple functions; map and reduce without the responsibility of running a distributed system.
The map function takes an input key/value pair and produces an intermediate key/value pair, the reduce function accepts an intermediate key and a list of all values associated with that key, and aggregates it into a single unit.
map(k1, v1) -> [(k2, v2)]
reduce(k2, list(v2)) -> list(v2)
A common application of this framework is in a distributed word counter program where you have a very large input file and want to count the occurrence of each word in the file. Instead of running this on a single machine, you divide the input file into smaller chunks (files) and distribute them across several machines (workers nodes).
The map function in this scenario takes in a key and value (file name and file content) and records each word along with its associated count in a file. The reduce function takes a word and a list of the associated counts and combines it into a single value.
map (filename string, filecontent string) -> {
for each word in filecontent
Emit(word, 1)
}
reduce (word string, occurences int[]) -> {
result := 0
for each value in occurences
result += value
Emit(word, result)
}
The MapReduce framework runs this computation across the various worker nodes. It uses a master node to coordinate which worker node runs a map or reduce function. It also handles potential failures within the cluster. Here’s an overview of how the library works.
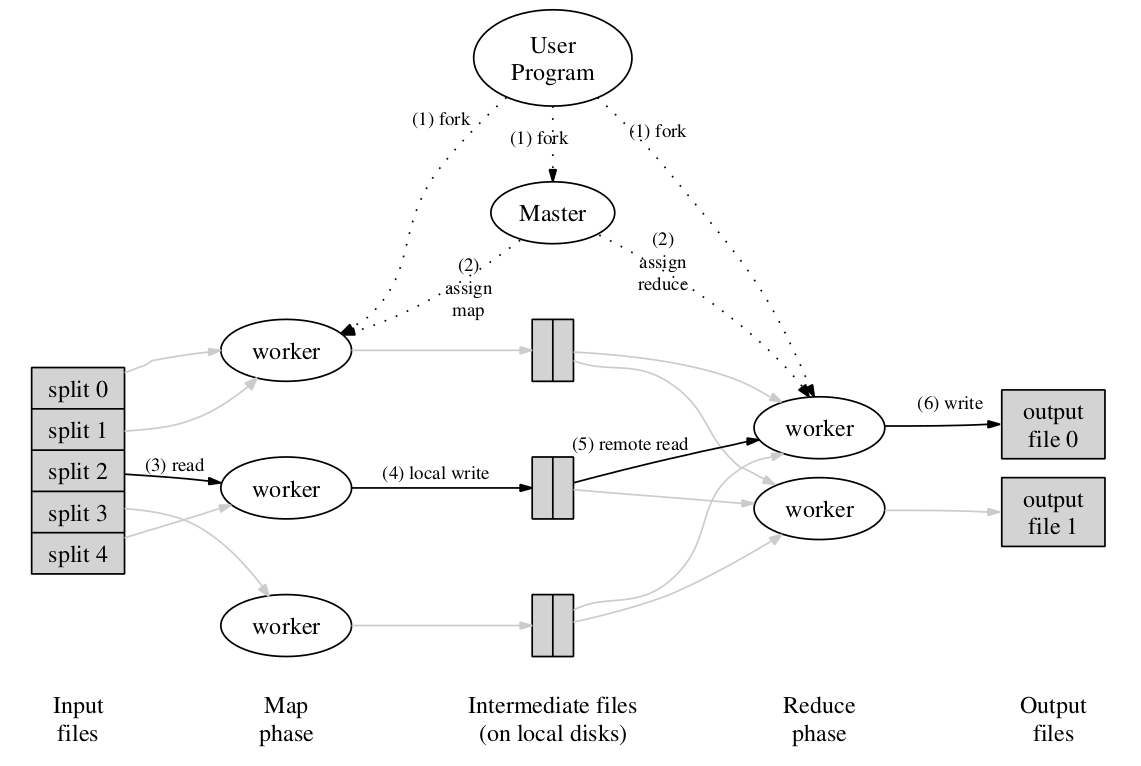
Fault Tolerance
The implementation uses a functional approach ie it doesn’t manipulate the input data files, allowing it to rerun mappers and reducers on the same data if needed. In case of failure of one or more worker nodes, it simply just re executes the computation on another idle or healthy node(s).
What if the master node fails, what happens then? The system crashes; there’s no mechanism to tolerate the failure of the master node.
Recent implementations avoid this by introducing a failover mechanism. For example hardoop has a
BackupNodethat is always synchronized with the state of the master node (NameNode). If theNameNodefails, theBackupNodecan be used to restore it since it has an up-to-date copy of its state.
Network Overhead
Workers already have the input data on their local file systems, allowing them to read the data without making expensive network calls. This is primarily true for ‘mapper workers,’ whereas ‘reduce workers’ have to make remote calls to get the output of the map function from their respective workers. Either way, the amount of network calls made within the system is significatly reduced.